

Distributed Thinking: A gentle introduction to distributed processing using Apache Storm and Apache Spark - Part 4
Welcome to Part 4 of Distributed Thinking! Here we discuss processing data streams. In case you missed anything, click here for Part 0.
2. Processing Data Streams
I’m glad you survived so far! Now let’s get down to processing things using technologies designed to process them, instead of relying on plain old Java Threads.
In the previous post, I discussed how to write a Word Count program using a threadpool in Java. Let’s quickly map that program into Storm and see how things work.
2.1. What is Storm?
![]()
Let me start off with a brief introduction to Storm. Storm started off as Twitter Storm, a technology to process the massive amounts of streaming Tweets that were pouring into Twitter.
I first used Twitter to actually process batches of data for a TV viewership product. Lots of lessons were learnt. Now it’s Apache Storm, and I know what it’s best used for. Our word counting problem isn’t exactly a “data stream” problem, but we can see how Storm can still help us bring up a distributed system to process the data anyway.
The major components of Storm can be explained with the image below:
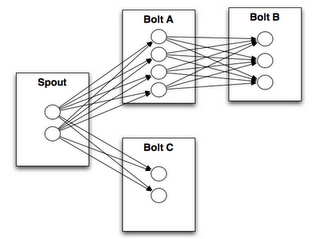
You can map this to the current system as follows:
- The Spout acts as a Data Source (We only need one Spout, though Storm supports multiple Spouts).
- The Bolts before the last level act as the Mappers/Filters.
- The Terminal Bolt acts as the Data Sink.
As Storm is designed to process continuous streams of data, it provides ways to retry processing of an object in the stream, but does not have an easy way to stop the system once it’s started.
A Storm system is started and made to process data streams continuously without stopping.
2.2. Word Count using Storm
Let’s look at how we’d map our Word Count problem in Storm and solve it:
The code consists of the following components:
- LineSpout - This
emitslines from the text file to be processed by downstream processes. - TokenizerBolt - This tokenizes the line into words, converts them to lowercase and
emitsit with a count of 1 - CounterBolt - This is the Data Sink which stores the data in a static Map. Ideally we’d write off the results into a database from one of the bolts, or use some other strategy of collecting the data.
- The
mainmethod - This submits the “Topology” to Storm for processing.
Here we kill the topology after a few seconds of execution, with the assumption that all the bolts are done processing the data left inside them. However it is important to note that it’s difficult to have a deterministic way to stop Storm as it’s not designed to be stopped after being started except when someone’s absolutely sure that they don’t want to process any more data.
I will discuss an elaborate strategy to make Storm a little more deterministic later.
Work in progress, please check back later
Click on any of the links below to go directly to any part:
Part 0: Introduction
Part 1: When and Where
Part 2: How to look at data
Part 3: How to look at data (continued)
Part 4: Processing Data Streams
Part 5: Processing Large Data Chunks